
Hey, it’s been a while since I wrote my last post! We’ve been quite preoccupied with hh → bbbb data analysis tasks and internal CMS presentations. I have several topics I want to talk about here so I will try to post more regularly in the following weeks. For today, I want to start a discussion about one important aspect of our job as scientists, which is software development.

Let’s consider the archetype of a member of this network, which we could define as an experimental particle physicist working at one of the LHC experiments, who is interested in statistical methods and machine learning. We will call him or her Andrea, which is a male name in Italy and female name in Spain, in order to to avoid cumbersome gender-neutral pronouns.
What is Andrea’s daily job like? Andrea spends most of Andrea’s time in front of a computer: replying to emails, attending video meetings, reading papers, putting together some results in a set of slides or a note and sometimes writes blog posts. Andrea is involved in several data analyses, which are not straightforward and benefit from advanced statistical learning techniques.
Andrea is also a proficient programmer in a sense, learned Fortran and C a while ago and is able to code almost anything using C-style C++ and the ROOT libraries. Andrea knows Andrea’s way around old school Unix commands and bash scripting, however modern tools or Python language do not seem very appealing to Andrea. Andrea works in data analysis’ code weekly and contributes to the experiment framework every so often.
However, most of Andrea’s code is somehow monolithic, it is not under version control or continuous integration and it does not include unit testing. It might also lack proper documentation and be hard to comprehend by Andrea’s colleagues. In other words, Andrea is not a software developer, but a scientist.
Software is an essential component of research for every scientific discipline nowadays. Well-developed and openly accessible scientific software libraries and programs can indeed accelerate scientific progress, especially for large scale and collaborative projects as the LHC. For example in the high energy physics field, a mixture of software packages (e.g. MadGraph, Pythia and Geant) are used for physics-driven simulations of the high energy processes and the interaction of their products with the detectors.
For most data analyses, researchers reuse the data definition format and utilities provided by ROOT. Furthermore, each experiment has its own custom software framework which integrates many libraries and tools with specific code and configurations. For example, the software framework of CMS, referred to as CMSSW is the largest scientific software product on GitHub (a popular repository for software source code) by number of commits (i.e. changes).
In addition to the experiment framework, each small analysis group usually has some shared code which is typically what the researchers actually work most of the time on. Therefore, a rather complex software ecosystem is required for carrying out data analysis at LHC and that without even considering the tools used to manage resources, data and jobs on the Grid (distributed computing infrastructure around the world) and local clusters.
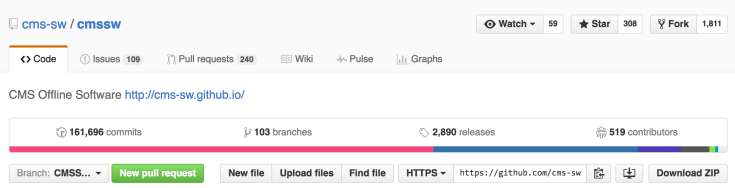
If most physicists do not follow software development best practises, how is a scientific software ecosystem as the one mentioned sustainable?
It turns out that Andrea is not an archetype member of this network nor of any LHC experiment. The level of expertise in software development practices in a scientific project varies greatly. Some people involved typically are awesome software developers and are able to integrate and manage code made by others as well as teach them.
Nevertheless, I really think that being a physicist is not an excuse for not following good programming style and practise when working with others, especially given the large number of learning resources currently available online. I am especially fond of two non-profit projects that focus on providing resources and organizing events to improve computing skills in scientific research. One is lead by Software Carpentry and the other is lead by Mozilla Science Lab. There you can find some nicely curated lessons on basic software development practices.
I am also thinking about writing a small series of posts/tutorials about some computing tools and practices that make my life easier as a researcher, and which might be also of use to you.
I would like to hear you opinion about this post, scientific software development or any other related topic, so don’t be shy in the comment section!

11 May 2016 at 14:27
Hi Pablo,
I’d certainly be interested in seeing some tutorial posts; I’m happy with my programming style, but my version control currently consists of Dropbox file recovery, though currently I am the only one who needs to use my code.
Also, at what point (size-wise/number of users-wise/complexity-wise) would you consider writing documentation beyond code comments?
Cheers,
Giles.
LikeLike
11 May 2016 at 17:59
Ciao Giles,
thank you for your feedback!
Even when your are the only one developer and user, using git (de facto standard for control version) provide several advantages over a Dropbox file recovery based workflow workflow: detailed history of changes, universal undo, try new things that affect to many files being sure that you will not spend much time going back in case you change your mind. It is also nice to see how you gradually make improvements. In case more people start using or developing your software you are all set. You can still keep your local copy on Dropbox but also one copy on GitHub or CERN’s gitlab.
Regarding documentation, in my opinion whenever you are working on something with several classes or functions, using some automated documentation generation system as Doxygen (or similar alternatives) from lightly annotated sources is nice both for C++ and Python and does not take much additional time. That being said, I do not follow the mentioned consideration that often, as you know we do not always have the time to set things properly. A README.md describing how to install and run is very useful even if you are the only user (would not be the first time I forget how to run my own program).
Cheers,
Pablo
LikeLiked by 1 person
12 May 2016 at 4:07
Hey Pablo,
This is my first visit to this blog, thanks to /r/physics. It piqued my interest because I happen to have graduated 3 years ago from the University of Chicago with a degree in Physics, and have since become a software engineer. Lately I’ve been thinking about starting on a path that would lead me closer to something in computational physics (or perhaps more specifically, computational physics).
That being said, if you know of any open source projects that need some engineering help, I would love to know about them.
Thanks for the post,
Steven
LikeLiked by 1 person
12 May 2016 at 18:47
Hi Steven,
happy you found us! Are you interested in any application of particular of computational physics (e.g. astrophysics, fluid mechanics, solid state physics or soft condensed matter) or the discipline itself?
Within High Energy Physics, which is the field I am currently working on, I know that the ROOT project (https://root.cern.ch/collaborate-with-us) is in need of manpower . However, the learning curve if you are not familiar with the library might be a bit steep.
Thank you for commenting,
Pablo
LikeLike
13 May 2016 at 0:27
Thanks for the reply Pablo!
Right now I’m happy to get any exposure, but astrophysics is probably what I’m more familiar with. I’ll look through the project and see if there’s any way I can help out!
Thanks again!
LikeLike
12 May 2016 at 7:35
The problem with writing code in physics: If you write good code, it will take you more time and you are considered to be slow by your peers. People that adapt the well written code can learn its intricacies efficiently and will be considered fast.
On the other hand, if you write sloppy code, you’re fast. Your peers will have a steep learning curve when using your code and will be seen as slow learners.
Bottom line: It pays to write bad code. Not for the experiment, not for your coding abilities, but for your reputation as a scientist. And given that we have to look for new jobs every other year, this is the most important thing.
LikeLike
12 May 2016 at 9:17
Whilst I am only an ‘early-stage’ researcher, and hence lack experience of the ins-and-out of research life and publication, I currently disagree with you:
Frequency of paper publication seems a bit of a first-order way of determining the overall quality of a researcher, rather than examining other factors, say quality and impact of work. Though I admit on a CV or an application form, one may appear more promising than someone else with fewer publications.
Contemporary research in this area is inherently collaborative, by necessity. To write code that is difficult to be understood and used by others, either deliberately or with the excuse that one will appear better than ones peers if they cannot easily use it, really doesn’t help anyone, including oneself if every other researcher adopts the same attitude.
Forgive my innocent idealism, but I currently believe that it doesn’t matter who does the research, only that it is done; one should be looking to actively help, not hinder, the research of others. Whilst I understand that contracts are short, and competition is high, I would choose to hire someone who was able to demonstrate that they were helpful and collaborated well with their fellow researchers over someone who simply had published a lot of papers.
I would also argue that developers of good code have a greater reputation amongst researchers. Why? Whenever their code is run, their name appears at the top of the terminal; their name appears in the relatively short author list of the documentation one cites, rather than being buried in the ‘et al.’ of a CMS or ATLAS author list (100s to 1000s of names); they’re normally quick to reply to queries and issues, and so build up a reputation for being helpful and reliable. I attended many interviews the past few years, and when asked about the people I’ve worked with, a lot more people recognised the names of those who had developed useful code than those who had purely done research.
LikeLiked by 1 person
13 May 2016 at 15:35
Excellent points Giles!
Nowadays software is not just a tools but an additional product of research, as valid as paper or conference publications. In fact, it is very easy to make research software easily citeable: https://guides.github.com/activities/citable-code/.
Cheers,
Pablo
LikeLike
14 May 2016 at 14:58
Thanks for the link Pablo, I hadn’t know it was that easy!
LikeLike
12 May 2016 at 12:08
I do agree with the general point you’re making there: physicist should not write the best code. That said I think it really pays off to follow the best practices that relate to documentation and understanding of the code, let me explain:
It makes no sense to spend time in high-level optimizations and compiler tricks because usually (and I am talking about science in general not only HEP) the computing time is much less that the time one spends coding; in that regard I do agree physicist should go for the easier, faster-to-write way of programming, even if it’s inefficient.
On the other hand, though, commenting your code, having a good version control system, proper installations and contribution guides… pays off. I have seen projects so badly documented (alas not very large ones) where it is actually more sensible to rewrite the code yourself rather than wasting time trying to understand what someone else did. Here is where developing best practices make a world of difference, even if you are the only developer for such project.
This is specially noticeable in those groups where coding is just a simple tool used to analyse small amounts of data in a very simple way. Is there where you end up with hundreds of small scripts that are non-reusable solely because you cannot remember (or check somewhere) what it did and it was like that. I work in such an environment and I can tell you that trying to force some best practices into my colleagues is greatly appreciated, though not always embraced as a way of working.
So to recap, my view on this topic is that as a physicist it doesn’t pay off to write beautiful elegant and efficient code, but it is a must to follow developing best practices when it comes to documentation, version control… mainly because we are not software developers.
LikeLiked by 1 person
13 May 2016 at 16:04
Hi Alvaro,
while I agree with you the elegance of the code should not be the figure of merit to optimize when writing scientific code, IMHO scientists should try to write the best code they can in terms of understandability by other scientists and future extendability. Furthermore, given enough programming experience, good code can be much easier (and faster) to develop for decent size projects.
See you around,
Pablo
LikeLiked by 1 person
12 May 2016 at 11:37
Hi Pablo,
I am relatively new to the field, working for my Masters’ in Physics and currently working full time for a commercial Software development company. During my Undergraduate, there was a module for computation using Numpy and Python, but it was purely the “lowest level” of abstraction – the syntax of the language. There was no mention of how to go beyond this to write efficient and clean code, or more crucially: how to collaborate with colleagues!
Science is built on collaborative projects, and as data analysis on a computer has become an *essential* part of that process, there needs to be a shift in how we perceive programming: not as a chore where code “mostly works”, but as a integral part of the scientific method
LikeLiked by 1 person
12 May 2016 at 11:56
I would really enjoy such a tutorial!
I’m about to start a career in physics and I’ve been programming a lot of c++ lately. I definitely identify with Andrea! In the last few months I’ve been transitioning from truly monolithic c-style -“functions only” c++ implementations of Monte Carlo algorithms into more structured code, learning appropriate data types, classes, templates and makefiles, git, etc., and there is still so much more to learn, especially if you also care about keeping performance.
My reasons for investing time in this are:
1) Reduced debugging time.
2) Larger programs become possible.
3) More reusable code.
4) Collaboration is now an option.
Even though there is plenty of jokes and horror stories about physicists coding, I haven’t found much about what to actually do, that is also up to date and appropriate for physicists. Tutorials seem to cater either to beginners learning syntax or to software devs on huge projects where it is assumed they already know much of the “meta” physicists lack. In my experience physicist mostly do console applications, very little ui, and rarely anything for end users but mostly for themselves or other collaborators on the same project. As such, the set of best practices and tools a physicist needs is probably a small subset of those for a proper software dev. Identifying that set “a priori” is quite hard and, most critically, it can take too much time away from actual physics. Compounding this issue, prominent forums often frown upon questions with opinionated answers, like “what tool should I use for X”, or “which set of tools should I use for a modern workflow?”, etc.
LikeLiked by 1 person
12 May 2016 at 15:40
Reblogged this on Delta de r.
LikeLike
13 May 2016 at 11:00
Hi Pablo,
very good post.
Your description of this hypothetical Andrea is so uncannily fit to my own profile that I have to decide whether to fill a lawsuit for defamation or not 😉
LikeLiked by 1 person
15 May 2016 at 21:22
Former computational condensed matter grad student here with work experience at a national lab who eventually left academia because I couldn’t take the vow of poverty.
Everything said this post was pretty much spot on in terms of my experience in a Ph.D. program.
Things I have seen:
* I have never met another physicist who knew what a version control system was. I guess there must be one or two out there somewhere, maybe sharing a git repo with Bigfoot, the Loch Ness monster, and a few unicorns.
* “Publish or Perish” plays into this a lot. Writing a really good software package from scratch to implement a new or improved computational method for ab initio calculations can take years. While it may be a very useful tool that expands the frontiers of computational physics one day, the time spent writing and testing it is time not spent publishing, which will have a negative impact on career advancement and funding. With the funding and employment situation being what it is, it is ultimately much more professionally rewarding to seek out “hot” topics currently en vogue that can be tackled with the tools available than to toil away in the thankless task of being the “shoulders of giants” that someone else stands on to take all the credit.
* To emphasize the above point, it wasn’t uncommon to find research groups that would outwardly sing the praises of openness and cooperation while inwardly jealously guarding and/or intentionally obfusticating everything about their code (right down to the variable names) so that no other group could feasibly use it until the authors had published at least ten or twenty papers using their new tool. Sometimes that would backfire when the two or three people working on the code got poached by tech companies, leaving an indecipherable mess of code for a couple of new grad students to struggle with in vain until the whole project died on the vine.
* Code quality was always considered second to publishing. So a grad student writes a 20,000 line, barely readable, unmaintainable monstrosity with everything in the main() function? Ok, well the data checks out, so we can publish this one-off paper and continue on our merry way. After all, it’s not like anyone will ever need to come back to this right? Even better, if they do, they’ll have to re-invent the wheel to do so, so we’ll be ahead of them. (Note that no thought is given to the fact that the people coming back to it later might be their future selves.)
* Even in grad school, I always felt like my programming knowledge was out of date because I was being taught coding by a professor in his fifties or sixties who obviously stopped learning anything more about coding in his twenties. But I never understood just how obsolete my knowledge from academia was until I started studying software development and engineering on my own time and later got an industry job. I’m not talking so much about choice of language as I am just general concepts and tools of modern development. Things like object-oriented programming, version control, bug tracking, unit tests, debuggers, documentation, and sometimes even code comments were anywhere from “unheard of” to “things not spoken of in polite company” everywhere I went in the academic world. Getting a job in the “real world”–that dark, hopeless hellhole of tormented, fallen souls that my professors warned me about–felt like stepping into a time machine and going a century or two forward into a science fiction setting, by comparison.
Bits of snark aside, I think what it boils down to is a system that punishes scientists who spend to much (or any) time on software quality and rewards those who skate by any way they can to get more papers and citations. But I left that pointless rat race a long time ago, so it isn’t my problem.
LikeLiked by 1 person
16 May 2016 at 6:56
I use svn for revision control and winmerge to compare files. Avoid most of C++ . stick to higly modular C code.
USe both UNIX GCC with -Wall enabled. And Ms visual C to catch live bugs.
I fix a lot of old buggy or half baked code. My current project has code 20 years old. And they lost the spec binder. There is a comment about a Vax bug fix.
They did not use revision control even though Svn was just sitting there on the redhat server. Got it installed.
LikeLiked by 1 person
17 June 2017 at 14:27
Hi Pablo,
I am an incoming Ph.D. student on LHCb and I found your post very useful/inspiring. I will follow closely to catch any tutorial or resource you cared to share with someone about to join the Collaboration.
Thanks a lot.
Blaise
LikeLike
11 October 2020 at 2:15
Hi Pablo,
Thank you for this amazing post about Software Development in Physics research.
I am a Software Engineer by profession(for last 4 years) and I have very good grasp of the field. But I have passion for Physics which I have loved starting from my High School, during my Masters in Electrical Engineering (one year full time research in Photonics). I had chosen Software Engineering as profession right after my masters to earn some money for the family’s immediate needs.
But now that I have the family’s financial needs sorted, I want to jump into a Physics PhD program and do some excellent research work. But I am finding it really hard to crack the wall of admission process, partly because of my non Physics background and partly because it is hard to pursue two mindsets(job and admission application) at once. I want to know from you, can my experience in the Software Engineering field be a USP(unique selling point) for the admission decision taking committees across various universities if I want to do theoretical research in Particle Physics?
LikeLike