
The week before last I was presenting an update of some of my analysis work to the rest of my group. The work involved developing a neural-network to classify particle-collisions at the LHC.
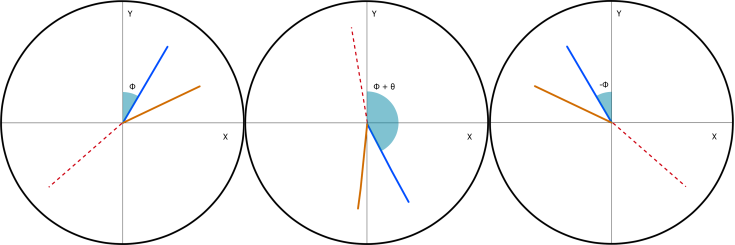
I mentioned that as part of processing the input data, I rotated all the events to have the same orientation; the detector has rotational symmetry in the plane transverse to the beam axis, and so the collision events can be expected to be produced uniformly across the azimuthal angle. By rotating the events to have a common orientation I remove the need for the classifier to learn this symmetry.
I also explained in passing that the alternative way to utilize this symmetry would be to apply random rotations to the events each time they are used. The classifier still has to learn the symmetry, but one can continually generate new training data. In terms of machine learning terminology, this would be train-time data-augmentation – making changes to a data-point in order to highlight some invariance to the classifier. For image recognition this could be zooming, flipping, rotating, or altering the colour levels:

These alterations can also be applied at test-time (test-time data-augmentation); it’s possible that the classifier might still contain some kind of bias (e.g. training images had cats all facing in one direction – real-life cats can face in multiple directions, or even more simply the test images are of different dimensions or aspect ratios to the training ones), so by taking the average prediction of the classifier for a set of augmentations of each image, it’s performance should be further increased.
I realised I’d never actually tried the random-rotation method; setting events to a common orientation had been easier to implement and gave a reasonable improvement so I had stopped there. I also wanted to try and see whether test-time augmentation could give an improvement when applied to HEP data. At the same time I was wondering whether there were any other symmetries I could exploit.
The LHC collides beams of the same type of particle at equal energy approximately head-on, the events should therefore exhibit a forwards/backwards symmetry (easily checked by looking at the eta-distributions of final-states) – flipping events in z-axis is therefore a valid transformation. So is flipping in either the x- or y-axes (flipping in both and rotating can reproduce the original event).

Readers may remember my last post in which I attempted the HiggsML challenge (an old physics-based Kaggle challenge). I’ll return to using this challenge data since it is public and contains a few subtle details.
This challenge was where I’d first tried setting a common azimuthal orientation and so as an initial test, I kept the common orientation and trained a new classifier applying flips in the x-, y-, and z-axes (since I have already rotated, flips in both x and y can produce new events).
Over cross-validation, the classifiers reached lower losses than they previously had. When I applied test-time augmentations, the performance on the validation was slightly better, too. Submitting prediction on the test data to Kaggle I got the highest private score I’d ever managed. Unfortunately, the public score was worse than some of my earlier submissions.
As a side note: It seems that many people had found large differences between their public and private scores and indeed between their validation and public scores. This seems to be due to the relatively noisy scoring metric and the public score being based on only 18% of the entire testing data. The take-home recommendation appeared to be to have a rigorous cross-validation procedure in place, and some method of ranking one’s solutions which didn’t rely too much on their public scores (entrants could only submit two solutions for final scoring).
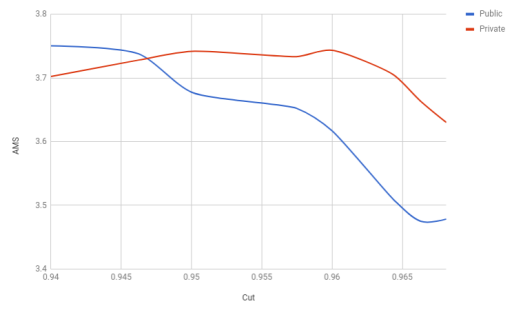
Indeed, when I scanned across possible cuts on my classifier, the private and public scores appeared to be offset, so optimising on public score would give a worse private score. NB. the private score was not visible until after the competition closed, so entrants would not be able to see this offset. Further message being, as well as comparing solutions well, a robust method of selecting the cut is required.
Still, I was feeling encouraged and went on to try rotating the events. Whilst it appeared to give an improvement in the training, it wasn’t as large as I’d hoped. On closer inspection I found a few problems: I work in a Cartesian coordinate-system, and when I apply the rotations I assumed that the axis of rotation was the origin, however since I first normalise and standardise the data, slight imbalances in the initial distributions can lead to the origin of the transformed data being shifted. In the case of some vectors this could be quite large: the data contains information about jets, which don’t always appear in the event and when they do not, they are assigned positions of -999, which has a significant impact when the data is normalised.
Eventually I moved to setting missing values to zero, and inverse-transform the data before applying any augmentations anyway. Rotation then gave the performance increase I’d hoped for, and when I trained using both rotation and x- and z-reflections I produced the best performing classifiers I’d seen.
Having trained with augmentations, I wanted to check whether test-time augmentation was still offering some improvements to performance and ran a variety of tests of different configurations on the validation sample.
Looking at the number of times the mean prediction for the test-time-augmented data was better than the single prediction on the original data, test-time augmentation always showed an overall improvement. However, in raw numbers the improvement appeared to be very low (~1 % of the time the mean prediction was better than the default prediction). Proper metrics on the validation data, however, were much higher, indicating that the times the mean prediction was better, the improvement was fairly large.
N.B. when I trained without augmentation, test-time augmentation had a much larger impact, the decrease in improvement with train-time augmentation is to be expected since the classifier has already been exposed to a more uniformly populated feature-space.
At this point I’d just been using a single classifier, however as part of my training procedure, I train an ensemble of ten classifiers. When I moved to running on the full ensemble I noticed a curious thing: the maximal AMS (metric used for Kaggle score) on the validation data became worse, however the ROC AUC improved.
The ROC AUC is a function of the entire sample, whereas the maximal AMS is due just to a single data-point, so it’s possible that the improved generalisation of ensembling corresponds to a smoothing of the AMS distribution, and the previously larger value had simply been due to sharp spikes in the distribution. Either way I was sure, however, that ensembling should always give an improvement, and indeed when I submitted scored tests to Kaggle, the score with ensembling was significantly better.
The result was actually very pleasing: 3.80860 private, 3.81668 public. Had I entered the competition, this would have just beaten the winning score of 3.80581 (I might have been a bit happy). My previous best had been 3.73439 private, 3.69002 public and I’d really struggled to do better than this with the various other methods in my toolbox, so it seems that test-time train-time augmentation will make a fine addition to my collection.
In summary:
- During training, the particle 3-momenta were randomly reflected in the z- and x-axes (e.g. px → -px) and rotated in 𝜙 by a random amount (e.g. px → px cos𝜽 – py sin𝜽).
- During testing each event was augmented and predicted 32 times per classifier (320 times for the full ensemble!). The full set of augmentations being eight equal rotations (fixed angle of 𝜋/4) per combination of reflections (possible reflections in two axes = 4 different possible combinations).
- The benefit of test-time augmentation eventually saturates in terms of number of augmentations; I reran using 16 rotations and it showed no benefit over using 8.
- Take care about pre-processing transformations that have been applied to the data – it might be quicker to fit the transformation and only apply it once the data has been augmented.
Seeing how well data augmentation worked on this particular challenge, I’m eager to see what improvements it will bring to the other problems I work on. There might well be other symmetries that could be exploited (e.g. the charge of particles could be swapped). However, the augmentations described here should be generally applicable to most classification problems in high-energy physics.

26 April 2018 at 10:49
> e.g. the charge of particles could be swapped
Be careful when the background has only one “native” lepton, like W+jets; not only the amount of this kind of background is asymmetric (more W+ than W-) but also the kinematics may differ, because valence up and down quarks have a different Bjorken-x spectrum than sea quarks.
LikeLike
26 April 2018 at 11:14
Hi Andrea, thanks for the pointer; indeed I’d not considered that the kinematics might be dependent on charge.
LikeLike