
Today I learned a lesson the hard way – in a nutshell, the lesson is that you should not forget what you yourself teach!
During my “Statistics for Data Analysis” lectures at the PhD course in Padova (and elsewhere – for instance here, here, here, and here) I usually start the course by drawing the students’ attention to the pitfalls of mistaking one statistical distribution for another in a given problem. And the way I do it is by citing one particular example when two physicists were led to believe they had found a signal of free quark in cosmic ray tracks detected by a bubble chamber.
 I have discussed that story elsewhere so I won’t repeat it here, but the gist of it is that the physicists mistook the number of bubbles that a track leaves in the detector as a Poisson-distributed quantity, while it is in fact distributed as a Compound-Poisson-distributed one (bubble formation by particle-ion collisions is a random Poisson process, but the number of created bubbles is also Poisson-distributed). This made the physicists believe that the low-ionizing track they had seen had to have a fractional charge, as the number of bubbles was too low – they estimated the probability using the Poisson distribution instead than the compound one. Big mistake, and a spectacular failure (with a published paper there to witness it).
I have discussed that story elsewhere so I won’t repeat it here, but the gist of it is that the physicists mistook the number of bubbles that a track leaves in the detector as a Poisson-distributed quantity, while it is in fact distributed as a Compound-Poisson-distributed one (bubble formation by particle-ion collisions is a random Poisson process, but the number of created bubbles is also Poisson-distributed). This made the physicists believe that the low-ionizing track they had seen had to have a fractional charge, as the number of bubbles was too low – they estimated the probability using the Poisson distribution instead than the compound one. Big mistake, and a spectacular failure (with a published paper there to witness it).
Incidentally, the compound Poisson is defined by the formula below, where you see that we are dealing with the sum of N Poisson variables of mean μ, when N is also a Poisson variable of mean λ:

(On the right above is the picture of cosmic ray tracks as seen by the bubble chamber which took the data on which the claim of free quarks was based).
It is nice to laugh at the delusional physicists who believed they had made a giant discovery but ended up embarrassed by their publication; however, today I made the same mistake, during some studies aimed at determining a systematic uncertainty on the background shape model we are going to use for the search of Higgs pair production events in the four-b-quark final state.
What Pablo, Martino, Mia, Alexandra and I are doing in Padova is to search CMS data for events with four b-quark-jets. After a selection, we need to model the distribution of reconstructed Higgs boson masses expected from backgrounds, such that we can become sensitive to the presence of a real signal.
We do have such a model. I have discussed briefly how we obtain the model in a former post. Once we construct the model, we may compare true data and model by considering the bin contents in the part of the histograms away from the possibly signal-rich mass region. If we do that, we find a good agreement – but we cannot estimate how “different” real data and model are; while we would like to have a measure, which we can quote as a “modeling systematic uncertainty”.
So we use the Bootstrap technique. The Bootstrap, due to Brian Efron, is a dear friend of mine as a statistical technique, as I was fascinated by it as a kid, when I read a 1981 article “Computer-Intensive Methods in Statistics” by Brian Efron himself on “Scientific American”. The Bootstrap consists in drawing at random M elements from a sample of N>M, thus creating a subset of the original. Since there are *many* ways to do that, you can obtain a large number of subsets. With them you can effectively study the statistical properties of the original data.
One crucial point of the Bootstrap is that once you draw an event from the original set, you are not really removing it but copying. So your subset may end up containing multiple copies of the same event. This does not harm in general, but you must be careful in some specific cases.
In my setup I have two datasets of N events (original data and model). I draw M events from each, and create two histograms A and B. The histograms have bin contents 
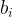


![\displaystyle P = [a_i-b_i] / \sqrt{a_i + b_i}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+P+%3D+%5Ba_i-b_i%5D+%2F+%5Csqrt%7Ba_i+%2B+b_i%7D&bg=ffffff&fg=000000&s=1&c=20201002)
as the variance of
Alas, if you study the distribution of P you find that it is not a Gaussian with a mean of zero and a RMS of 1, as you would expect if the original distributions A and B were drawn from the same parent distribution (the “null hypothesis” in this setup). Instead, you find that the RMS increases as M approaches N. This precludes any conclusion on the validity of the null hypothesis.
I have simplified a lot the problem in the above discussion because I did not want to confuse you as much as I managed to confuse myself… Suffices to say that it took me a full day (or better say one night of sleep) before I could realize that I had fallen in the same trap of the two physicists who thought they had discovered free quarks in bubble chamber data!
The mistake is, in fact, that the bin contents in Bootstrap-resampled data are *not* Poisson-distributed. They are distributed according to the compound Poisson! This is because when M is not very much smaller than N, there is a non-negligible probability that an event is taken multiple times to create a subset. Thus, in each bin of the bootstrapped distribution containing, say, C events, there are fewer than C independent events. It so turns out that the variance of the bin content C is not C itself as in the Poisson case, but C*(1+M/N). This makes the distribution of pulls P defined above wider than 1, if one uses the wrong variance to compute the denominator of P…
Take that, Statistics Professor. I should have known better from the start!
(Feature image credit: Nature.com)

17 May 2016 at 1:41
Got it!
LikeLike
17 May 2016 at 20:51
I think you mean Bradley Efron
LikeLiked by 1 person
17 May 2016 at 22:43
You’re obviously right ! Thanks!
LikeLike