
If I introduce myself as a statistician, people often react: “You should teach me how to win the soccer bets and lotteries”. Then I try to explain that every hazard game is designed so that the mean revenue is positive for a casino or a lottery owner. But many people still try to find a way to break the system and “fool” an underlying statistical model. Is it ever possible?
Lately I attended an interesting lecture about the Extreme Value Theory. It is the study of the distribution of maximal observation. As a simple example suppose we have n independent and identically distributed (i.i.d.) random variables from a uniform distribution U(0,1). We could be interested in the probability that the maximum is lower than a given threshold t from the set (0,1).
In this case
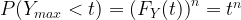
where 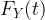

In the last year the Extreme Value Theory has gained much attention. It has a huge importance in applications in for example financial market, soccer bets or natural sciences. Extreme value distributions are often heavily tailed, so events of 5 sigma distance from the mean are quite likely to occur.
Let us consider the sea level in Venice. As the city is built right above the water it is often flooded. If we were to build a dam to protect the city from getting flooded it would be crucial to know the maximum level of the sea. Certainly there is a possibility of building a 10 meter high barrier, but the cost would be unbearable and the landscape would be destroyed.
Therefore the question: how high should the dam be to protect the city?
Below you find a plot of the 10 maximal daily sea levels, aggregated by years. On the y-axis there is the difference between mean and observed sea level in centimeters. Besides a visibly positive trend we notice many “outliers”. These are the extreme days of floods the dam needs to protect the city from.

Using R and its packages “ismev” and “evir” we can find the Maximum Likelihood estimates for the Generalized Extreme Value Distribution model. Given the model we can calculate the probability that for example the maximal difference of the sea level in the next year will exceed 160 cm. In this case it is equal to 2.2%. We could also calculate the height of a dam that on average would let the flood pass only once in hundred years. For a given model we obtain 166.4 cm.
So far we haven’t considered the trend that turns out to be statistically significant. Therefore our data is not stationary and that was an assumption needed to build the previous model. Consequently we should complicate the model and add the trend, but I don’t want to make this article too complicated.
I’m quite fascinated by this theory and modeling scheme. I see a huge potential in testing for High Energy Physics. The rare events like Higgs production often have a non Gaussian distribution with heavy tails. If treated like standard Gaussians we might obtain significant differences from background and these yield a false discovery. Therefore we should be very careful with any inference.

14 December 2016 at 18:29
I visited a lot of website however I this one this one holds a lot
of informative stuff.
LikeLike
11 February 2023 at 13:20
Thanks for writing such a good article, I stumbled onto your blog and read a few post.I like your style of writing
we provide Casino site | Baccarat site | Online Casino | Baccarat | Casino – Recommended Onka
카지노사이트
LikeLike